Natural language processing (NLP) has many applications such as:
- Machine Translation: translation of words or sentences from one language to another
- Automatic Summarization: summarizing the paragraph in one sentence
- Sentiment Analysis: identify sentiments (positive/negative/neutral) in various posts
- Text Classification: classifying a set of documents to some categories
- Question Answering: given a corpus, finding the answer to a question
- Sequence Models: text generation, music generation
Text Generation
Text Generation is a type of Language Modelling problem. A trained language model learns the likelihood of occurrence of a word based on the previous sequence of words used in the text. Language models can be operated at character level, n-gram level, sentence level or even paragraph level. Recurrent Neural Networks (RNN) can be used to create the language models for generating natural language texts.
Why RNN?
Basic layered neural networks are used when there are a set of distinct inputs and we expect a class or a real number etc.. assuming that all inputs are independent of each other. RNNs are used when the inputs are sequential. This is perfect for modelling languages because language is a sequence of words and each word is dependent on the words that come before it. If we want to predict the next word in a sentence, we should know what were the previous words.
An example is “I had a good time in France. I also learned to speak some _________”. If we want to predict what word will go in the blank, we have to go all the way to the word France and then conclude that the most likely word will be French. In other words, we have to have some memory of our previous outputs and calculate new outputs based on our past outputs.
Problems with basic RNN
Exploding Gradients and Vanishing Gradients
Gradients: A gradient is a partial derivative with respect to its inputs. In simple words, A gradient measures how much the output of a function changes, if you change the inputs a little bit.
Exploding Gradients: Exploding gradients are a problem where large error gradients accumulate and result in very large updates to neural network model weights during training. This has the effect of your model being unstable and unable to learn from your training data. But, this problem can be easily solved if you truncate or squash the gradients.
Vanishing Gradients: In some cases, the gradient will be vanishingly small, effectively preventing the weight from changing its value. In the worst case, this may completely stop the neural network from further training.
Solution: Long Short Term Memory (LSTM) and Gated Recurrent Unit (GRU)
LSTM and GRU
These networks are capable of remembering long-term dependencies. They are designed to remember information for long periods of time without having to deal with the vanishing gradient problem. They have internal mechanisms called gates that can regulate the flow of information. These gates can learn which data in a sequence is important to keep or throw away. Thus, it can pass relevant information down the long chain of sequences to make predictions.
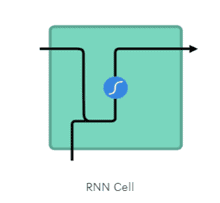
Architecture of LSTM and GRU
Architecture of LSTM and GRU cells with respect to basic RNN cell. Following we can see, how LSTM and GRU cells are different from regular RNN cell.
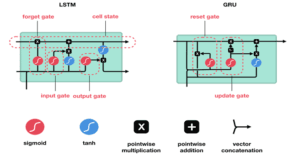
Differences between LSTM and GRU
The key difference between a GRU and an LSTM is that a GRU has two gates (reset and update gates) whereas an LSTM has three gates (namely input, output and forget gates). LSTMs remember longer sequences than GRUs and outperform them in tasks requiring modeling long-distance relations in language modelling problems. GRUs train faster and perform better than LSTMs on less training data for language modeling problems. GRUs are simpler and easier to modify and has less code in general.
Implementation of LSTM model in Keras
A very simple implementation of LSTM model in Keras:

Bi-Directional LSTM
Unidirectional LSTM only preserves information of the past because the only inputs it has seen are from the past. Using bidirectional will run your inputs in two ways, one from past to future and one from future to past. Bidirectional LSTMs train two instead of one LSTMs on the input sequence. The first on the input sequence as-is and the second on a reversed copy of the input sequence. This can provide additional context to the network and result in faster and even fuller learning on the problem. What differs this approach from unidirectional is that: in the LSTM that runs backwards you preserve information from the future and using the two hidden states combined you are able in any point in time to preserve information from both past and future. Bi-LSTMs show very good results as they can understand context better.
Example where Bi-LSTM performs better
Lets say we try to predict the next word in a sentence:
The boys went to ….
Unidirectional LSTM will see just “The boys went to ” to predict the next word.
Whereas, Bi-LSTM will see information from the future as well in backward LSTM pass.
Forward LSTM pass will see: “The boys went to …. ”
Backward LSTM pass will see: “… and then they got out of the pool ”
Thus, using the information from the future it is easier for the network to understand what the next word is.
Implementation of Bi-LSTM model in Keras
A very simple implementation of Bi-directional LSTM model in Keras: